EVI Version
EVI 3 and EVI 4-mini are the currently supported versions of Hume’s Empathic Voice Interface. EVI 1 and EVI 2 reached end of support on August 30, 2025. This guide explains how to set the EVI version in Chat and provides a migration path for integrations using EVI 1 or EVI 2.
How EVI version is applied
The EVI version is resolved from the Config you use to start a Chat.
- Provide a
config_idwhen you start the Chat. - The service loads that Config and reads its evi_version.
- The Chat uses that version for its lifetime.
If you omit config_id, the Chat uses EVI 3 by default.
Set the EVI version
The EVI version is set using the evi_version field in your
Config. The version associated with the
config_id you provide when starting a Chat determines which EVI version is used.
Update an existing Config
To change the version of an existing Config:
- Go to the Configurations page.
- Find your Config by name and click Edit.
- Select a different version from the edit page.
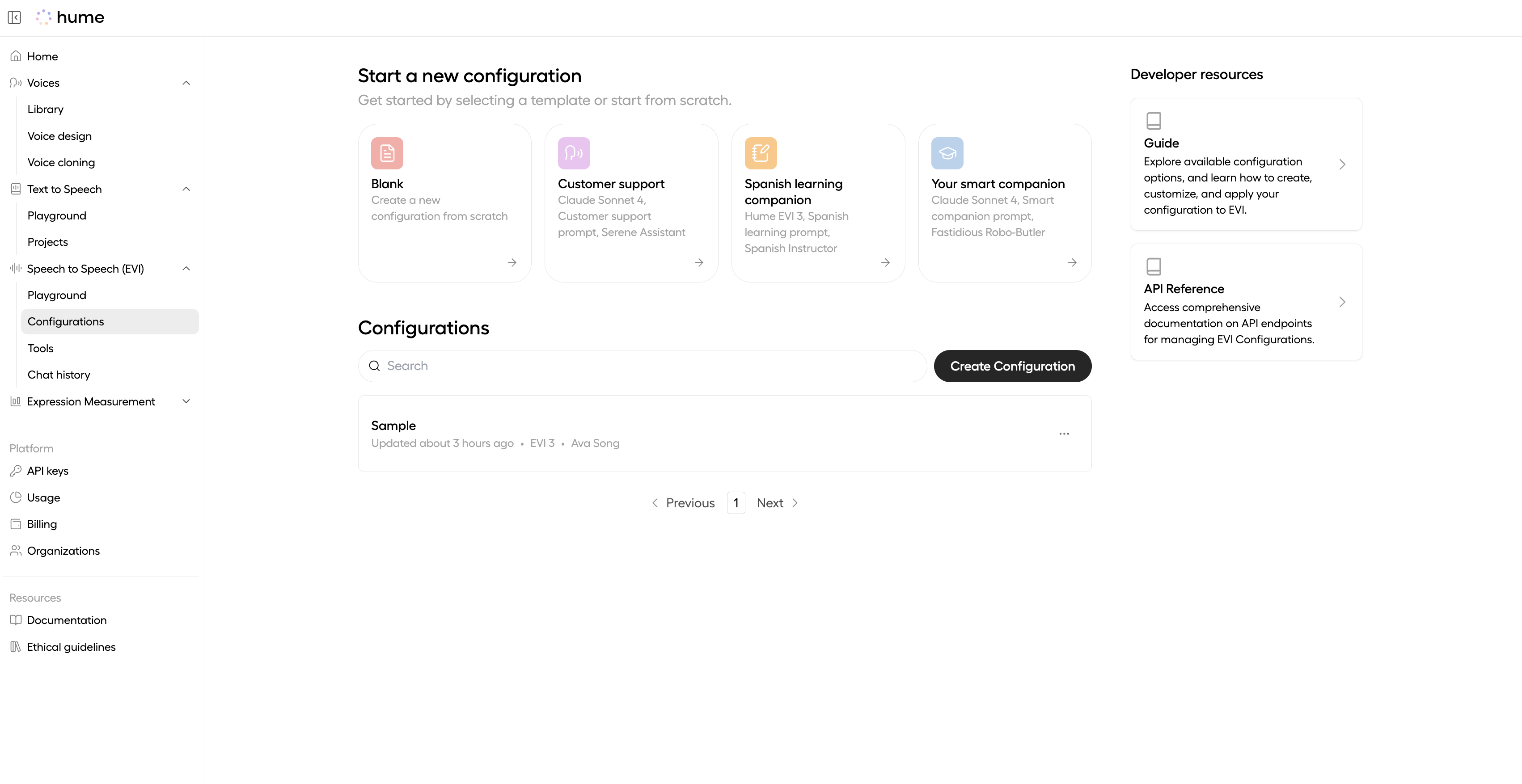
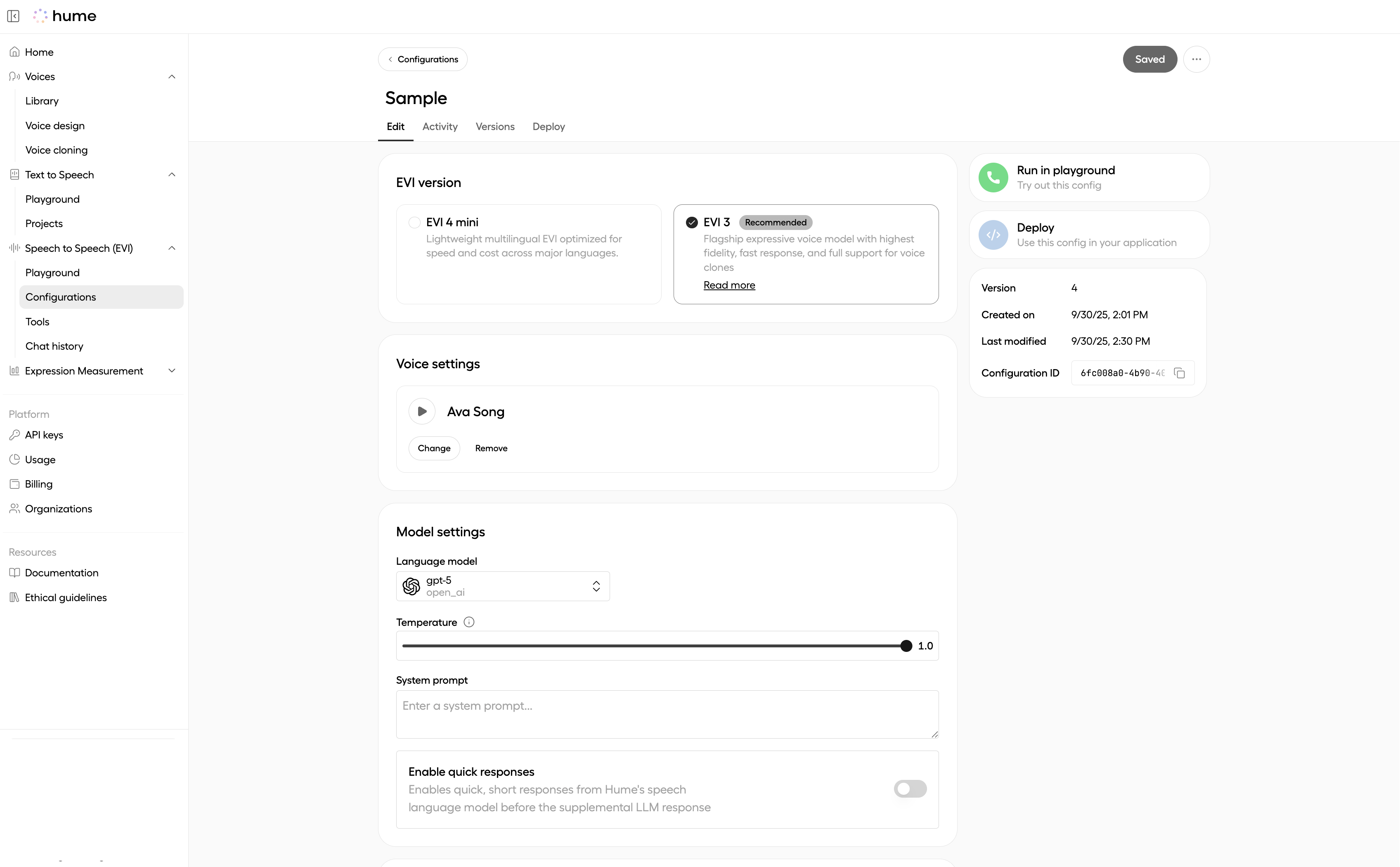
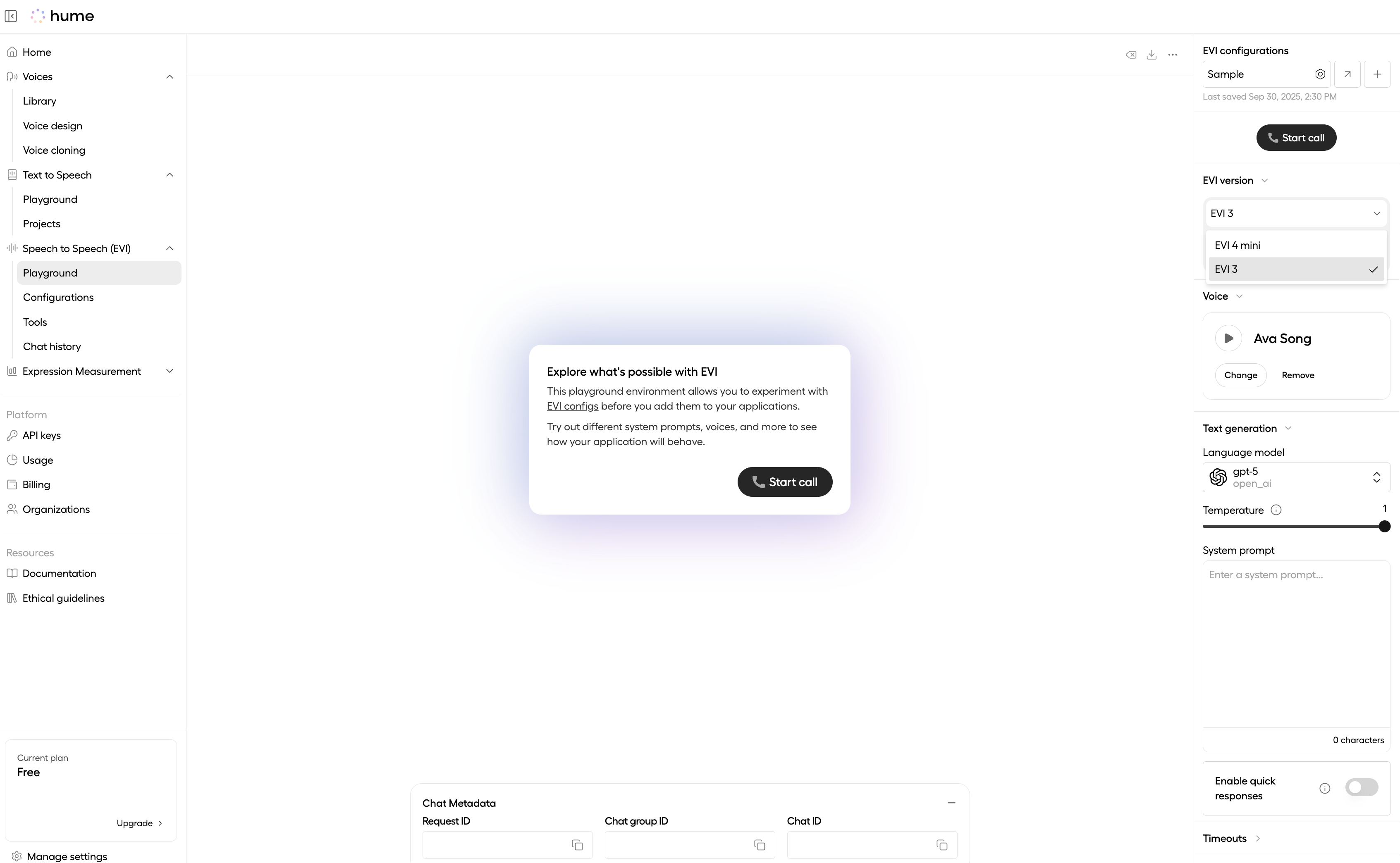
You can also update the version directly in the EVI playground by selecting a Config and changing the version in the panel on the right.
EVI 4-mini guide
Changes
-
EVI 4-mini is multilingual
-
Impact: EVI 4-mini supports the following languages: English, Japanese, Korean, Spanish, French, Portuguese, Italian, German, Russian, Hindi, Arabic.
-
Action: Create a new voice with a prompt in the language you’d like to use.
-
-
Latency improvement
- Impact: The model latency improvement is ~100ms on each response.
This section details the changes required to migrate from EVI 3 to EVI 4-mini. If you are migrating from from EVI 1 or 2, please refer to the section below first.
Upgrade instructions
If you’d like to migrate to EVI 4-mini:
- Set the
evi_versionfield in your Config to"4-mini". - Follow the steps in Update an existing Config to apply the change.
Summary
Migrating to EVI 3
Instructions on migrating from EVI 1 or 2
This section details the changes required to migrate from EVI 1 or 2 to EVI 3, including Config updates, SDK upgrades, and client-side message handling.
Upgrade instructions
To upgrade to EVI 3:
- Set the
evi_versionfield in your Config to"3". - Follow the steps in Update an existing Config to apply the change.
SDK compatibility
The following are the minimum SDK versions compatible with EVI 3. If you’re using an older version, update it using the commands below.
The versions below are minimums. For the newest EVI 3 features, performance improvements, and security fixes, upgrade to the latest SDK releases. If you run into issues, update to the latest version before troubleshooting.
React SDK (v0.2.1)
TypeScript SDK (v0.12.1)
Python SDK (v0.10.1)
Breaking changes
-
EVI 3 introduces a new voice system
-
Impact: Voice options from EVI 1 and 2 are not compatible with EVI 3.
-
Reason: EVI 3 is powered by a speech-language model that supports an expanded, high-quality set of voices.
-
Action: Use a voice from the Voice Library or your Custom voices.
-
-
Voice selection is now required
-
Impact: Configs that do not specify a voice must now include one.
-
Reason: There is no default voice for EVI 3.
-
Action: If your Config does not already specify a voice, update it to include one from the supported options. Our voice library includes EVI 3 clones of the popular ITO and KORA voices from EVI 1 and 2.
-
-
Assistant prosody is delivered separately
-
Impact: Prosody scores are no longer included in
assistant_messagepayloads. -
Reason: In EVI 3, prosody scores are sent asynchronously in a separate
assistant_prosodymessage. This allows for lower latency during speech synthesis. -
Action: Use the shared
idfield to associate eachassistant_prosodymessage with its correspondingassistant_message.
Assistant MessageAssistant Prosody Message -