Voice Design
A guide to designing expressive, natural-sounding voices using Octave, Hume’s speech-language model.
Octave enables you to design custom voices using intuitive, descriptive prompts. This guide explains how voice design works, shares best practices for writing effective prompts, and demonstrates how to create reusable voices in the Platform UI and API.
How voice design works
Designing a voice with Octave involves guiding the model with both what kind of voice to generate and what that voice should say. These two inputs work together to produce expressive, character-consistent speech:
- Voice prompt (description): A natural-language prompt describing how the speaker should sound. This includes tone, personality, emotion, and context. The prompt sets the foundation for the voice’s identity.
- Input text: A sample line that fits naturally with the character’s voice and identity. It gives the model a reference for delivery—helping it match tone, pacing, and emotional nuance to the prompt.
Octave uses both inputs holistically. It doesn’t treat the prompt as a set of isolated traits—it interprets it in full context, just as a human would when imagining a speaker. The model then generates speech that reflects not just the words, but the personality behind them.
This allows for a wide range of voices: warm and professional, anxious and fast-paced, playful and sarcastic—even when the text stays the same. You can iterate quickly: revise your prompt, try alternate lines of text, and fine-tune the result by pairing tone, identity, and delivery.
In the next section, we’ll explore practical techniques for crafting clear, expressive voice prompts that lead to more natural, accurate results.
Crafting voice prompts
Octave understands language in context. The more clearly you describe who’s speaking and how they should sound, the more naturally the model will bring your voice to life.
-
Character and setting: Octave produces more expressive, natural speech when it understands:
- Voice identity: personality, tone, emotional quality
- How they speak: pace, clarity, intensity
- What context they’re in: setting, role, or intent
-
Voice profile: When writing a prompt, consider including details like:
- Tone: “serious”, “playful”, “melancholic”
- Speaking style: “clear”, “fast-paced”, “informal”
- Emotion or attitude: “cheerful”, “anxious”, “skeptical”
-
Formatting: Use standard formatting conventions to help Octave interpret your input clearly. This improves how it handles phrasing, structure, and delivery cues:
- Use standard punctuation to support your intended phrasing, structure, and tone.
- Avoid non-speech markup or symbols, such as emojis, HTML tags, or Markdown formatting.
- Keep formatting clean and readable, reflecting how the sentence would be spoken aloud.
Below are a few sample voice prompts crafted by the Hume team.
Valley Girl
Hype Man
Pirate Captain
Create a custom voice
Once you’ve created a generation that captures the voice you want, you can save it as a custom voice. This stores both the speech and the prompt that shaped it, so the model can reliably reproduce the same vocal identity in future requests.
You can create and save voices using:
- The Platform UI – great for interactive exploration and refinement.
- The API – ideal for programmatic use cases, such as letting end users design and save voices in your application.
Using the UI
This section walks through the voice creation flow in the Platform UI, from generating samples to saving your voice.
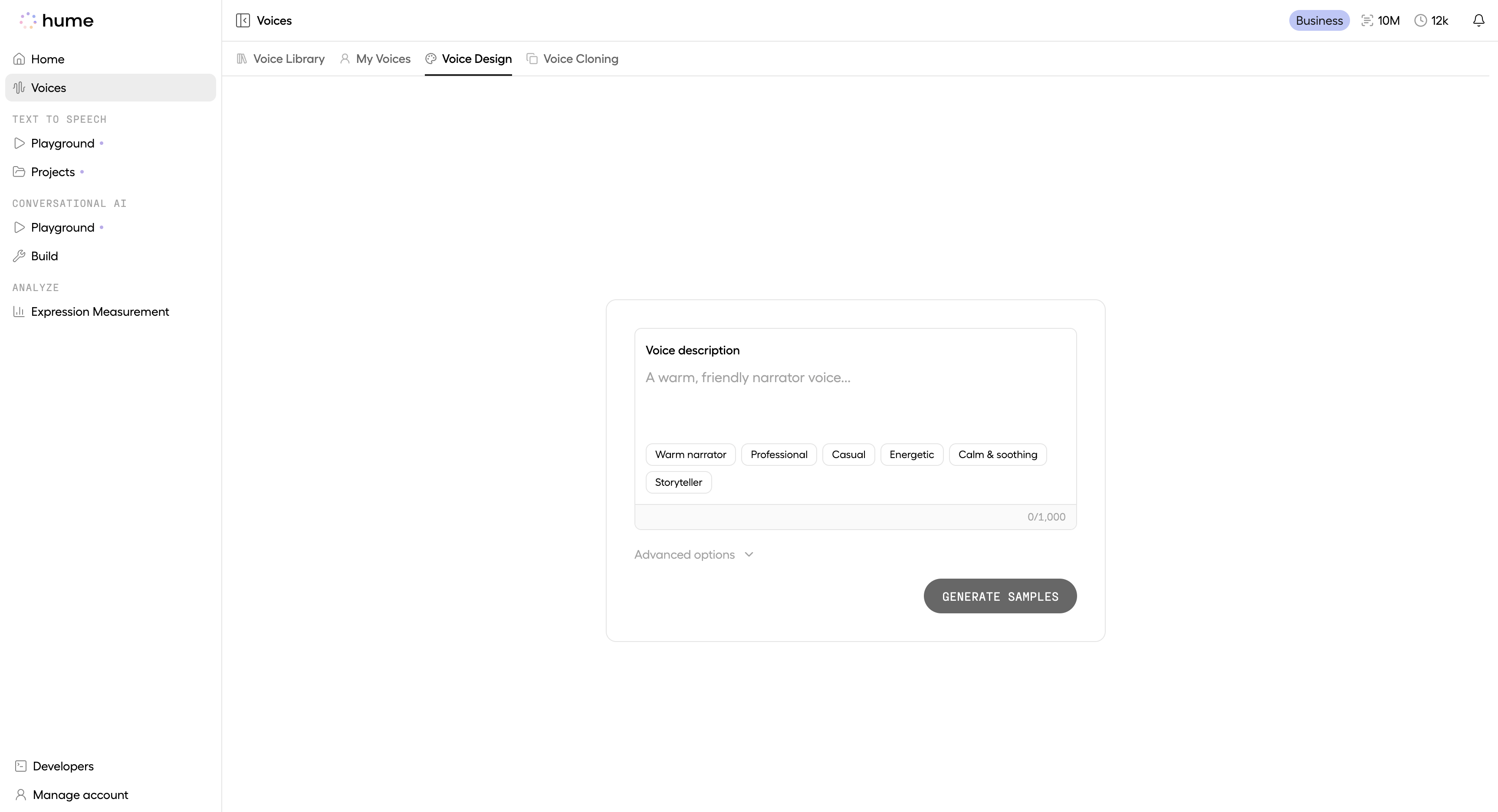
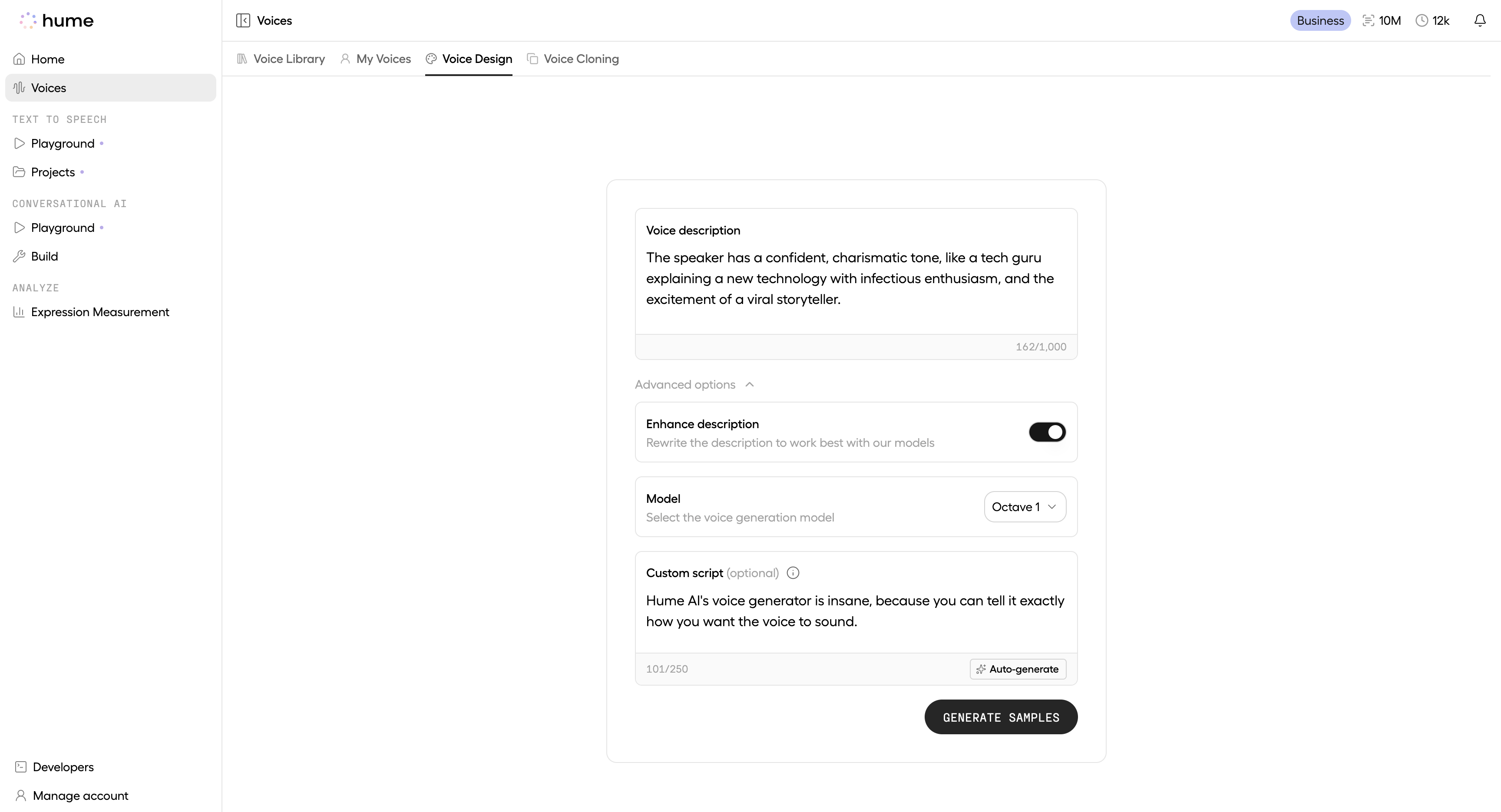
Input Text and Voice Prompt
Write your voice description. Optionally toggle Enhance description to rewrite it.
You can also choose your voice generation model and (optionally) the custom script you want to hear from the voice samples.
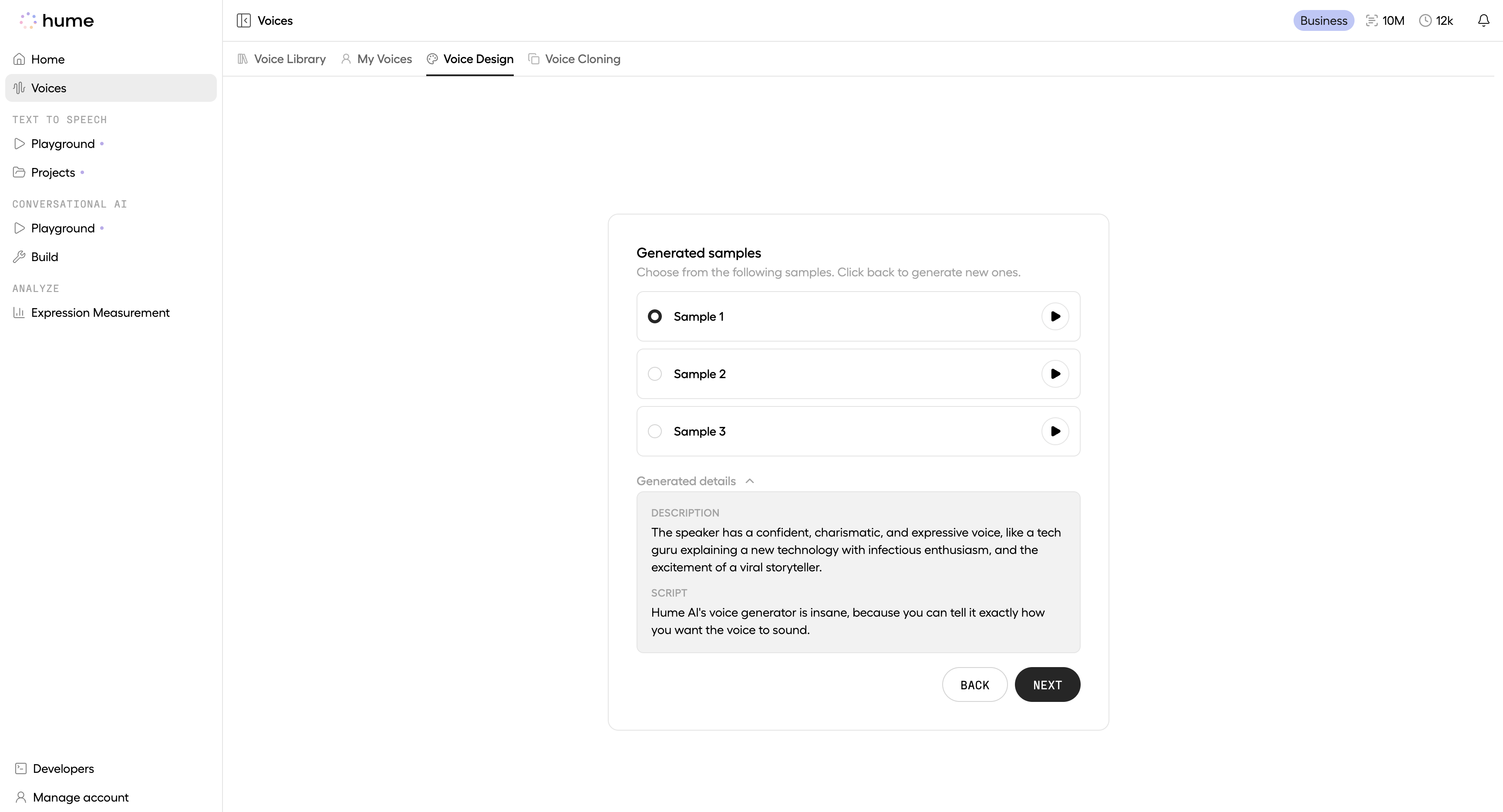
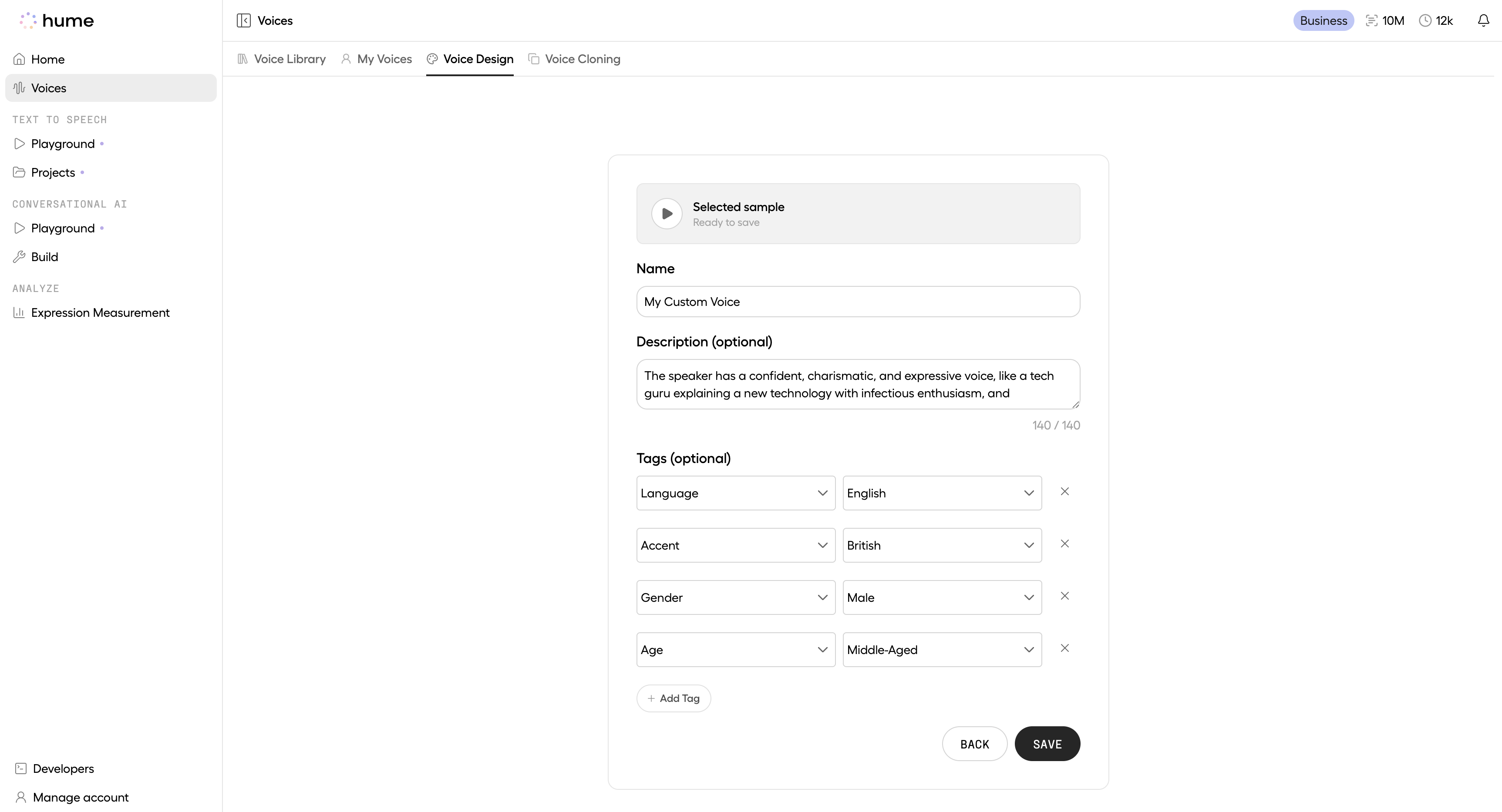
Using the API
This section walks through the voice creation API flow: generating speech in a new voice and saving that generation as a reusable voice.
Generate a voice
Generate a new voice by making a POST request to /v0/tts.
In the utterances field, include both a description and text.
You can optionally request multiple generations to explore variations.
The response includes one or more generations,
each with a generation_id, audio, and additional metadata.
Listen to each generation and choose the one you want to save. Use its generation_id in the next step to save
it as a voice.
Save the voice
Make a POST request to /v0/tts/voices to save a generation as a reusable voice.
Include the generation_id and a name for the new voice.
The response includes the name and id of your saved voice.
What’s next
You can use your custom voices across Hume products that support speech synthesis. Reference them by name or ID in TTS requests, or use them in EVI by specifying the voice in your configuration.
Use the playgrounds to preview how your saved voice sounds in different scenarios:
Chat with an assistant configured with your saved voice, to see how your voice sounds in conversation.
See how your saved voice sounds with specific text input, or when given acting instructions.
If you’re building an interface for others to create voices, you may also want to offer basic voice management—such as listing saved voices or deleting those no longer needed:
See guides below for details on how to use your voice in your project or integration.
Configure EVI to use your saved voice.
Specify a saved voice in your TTS requests.