Audio
Guide to recording and playing audio for an EVI chat.
Overview
This detailed guide explains how to be successful recording and playing back audio with EVI.
The best way to handle audio is to use the Hume AI React SDK @humeai/voice-react, which takes care of everything in this guide out of the box. If you are using the Hume AI TypeScript SDK directly, or connecting to EVI from a different programming language, follow the instructions in this guide to handle audio recording and playback correctly.
Things to keep in mind when working with audio in EVI:
- EVI is live. EVI audio is streamed, not pre-recorded. With EVI, you continuously send audio in small chunks, not whole files.
- EVI is a voice chat. EVI depends on advanced audio processing features like echo cancellation, noise suppression, and auto gain control, which must be enabled explicitly.
- Audio environments vary. Your users may be using different browsers, different devices, different operating systems, different hardware, and what works in one audio environment may not work in another.
Recording
Web
iOS
This section applies if you are using the Hume TypeScript SDK directly. If you are using the Hume AI React SDK (@humeai/voice-react), please refer to Next.js sections of the Quickstart guide.
Connect to EVI
Before recording, open a WebSocket connection to the /v0/evi/chat endpoint. For more context, see the TypeScript quickstart guide.
Client-side, not server-side - Typically, you should open the WebSocket connection to EVI on the client-side: either from your web frontend in JavaScript that runs in the user’s browser, or from inside your mobile app, because the server-side does not have direct access to the user’s microphone. Connecting to EVI from your backend is possible, but in this case you will have to transmit audio from the user’s device to your backend, and then from your backend to EVI, which will add latency.
WebSocket before Microphone - Connect to the EVI WebSocket before you start recording from the microphone. Audio formats like wav and webm begin with a header that you must transmit in order for EVI to be able to interpret the audio correctly. If the WebSocket connection is not ready when you begin recording and attempt to send the first bytes, you may inadvertently cut off the header.
Determine the audio format
Different browsers support sending different audio formats, described by MIME types. Use the getBrowserSupportedMimeType function from the Hume TypeScript SDK to determine an appropriate MIME type.
Start the audio stream
Use the getAudioStream helper from the Hume TypeScript SDK. This enables echo cancellation, noise suppression, and auto gain and wraps the standard MediaDevices.getUserMedia web interface.
Use the ensureSingleValidAudioTrack helper to make sure that there is a usable audio track. This will throw an error if there isn’t a single audio track (for example, if the user doesn’t have a microphone).
Record, base64 encode, and transmit
Use the MediaRecorder API to record audio from the microphone. Inside the .ondataavailable handler, encode the bytes of the audio into a base64 string and send it in an audio_input message to EVI.
Add support for muting
Most EVI integrations should allow the user to temporarily mute their microphone. The standard way to mute an audio stream is to send audio frames filled with empty data (versus not sending anything during mute). This helps distinguish between a muted-but-still-active audio stream and a stream that has become disconnected.
The above code snippets are lightly adapted from the EVI TypeScript Example. View the full source code on GitHub to see the complete implementation.
Playback
At a high level, to play audio from EVI:
- Listen for
audio_outputmessages from EVI and base64 decode them. - Implement a queue to store audio segments from EVI. Audio from EVI can arrive faster than it is spoken, so EVI will cut itself off if you play audio segments as soon as they arrive.
- Handle interruptions. You should stop playing the current audio segment and clear the queue when the
user_interruptionoruser_messageevents are received.
Web
iOS
Receive audio
After connecting to EVI, listen for audio_output messages. Audio output messages have a data field that contains a base64-encoded WAV file. In a browser environment, you can use the convertBase64ToBlob function from the Hume TypeScript SDK to convert the base64 string to a Blob object.
Play the audio from a queue
EVI can generate audio segments faster than they are spoken. Instead of playing the audio segments directly, you should place them into a queue on receipt.
To play an audio segment, convert the Blob to an Object URL use the Audio constructor from object from the browser’s HTMLAudioElement API, and call .play. Use the .onended listener to know when the segment has completed and play the next segment in the queue.
Handle interruption
EVI produces a user_interruption event if it detects that the user intends to speak while it is generating audio. However, it is also possible that a user will speak after EVI has finished generating audio for its turn, but before the audio has finished playing inside the browser. In this case, EVI will not produce a user_interruption event but will produce a user_message event. In both cases, you should stop the currently playing audio and empty the queue.
Enable verbose transcriptions to prevent interruption delays
By default, user_message events are only sent after the user has spoken for enough time to generate an accurate transcript. This can result in a perceptible delay in the user’s ability to interrupt EVI during the period when EVI is done generating its audio for the turn but before the browser has finished playing it.
To address this, you should set the query parameter verbose_transcription=true when opening the WebSocket connection to the /v0/evi/chat endpoint. This will cause EVI to send “interim” user messages, with an incomplete transcript, as soon as it detects that the user is speaking.
You should use these interim messages to stop the currently playing audio and clear the queue. Modify any other logic that uses
the transcript from user_message events to either ignore messages
with interim: true, or take into account how several interim
messages transcribing the same segment of speech may be sent before
the final message.
Handling complex audio scenarios
Users sometimes have multiple audio devices, play audio from multiple sources, or unplug devices while your app is in use. You should think about how your app should behave in these more complex scenarios. The answer to these questions will vary based on the purpose of your app, but here is a list of scenarios you should consider:
-
Graceful permission handling - Always check for audio permissions before starting to record audio. If the user has not granted permission, display an appropriate message and give the user instructions how to grant the permission.
-
Device selection - Simple EVI integrations can hardcode the default microphone and audio playback device. Consider what to do when there are multiple devices available. Should you default to headphones, if they are available? Should you allow the user to select a device?
-
Device unavailability - Users unplug audio devices, or revoke permission to record audio. In this case, fall back to a different audio device if appropriate, or pause the chat and display a message to resume.
-
Background audio - If you are building a mobile app, does it make sense for your app to be able to play audio in the background (for example, if the user switches apps to go look something up in a web browser)? What should happen when the user starts a chat but there is already audio playing in the background (listening to music, perhaps), should your app interrupt it?
Understanding digital audio
A common source of issues when building with EVI is malformed or unsupported audio. This section explains what audio formats EVI supports, gives some conceptual background on how to understand digital audio more generally, and gives some advice for how to troubleshoot audio-related issues.
Audio formats
Hume attempts to accomodate the widest range of audio formats supported by our tools and partners. However, we recommend converting to one of the industry’s most commonly supported audio formats for the sake of your own troubleshooting. Two excellent choices are:
- Linear PCM - A simple format for uncompressed audio that is easy to convert to and is supported by most audio processing tools.
- Audio/webm - This format is a web standard that allows sending compressed audio. It is supported by most browsers.
Audio/WebM
WebM is a container format that contains compressed audio, supported by all modern browsers.
A WebM audio stream begins with a header that identifies the stream as being WebM, with metadata describing the codec with which the audio is compressed and other details about the audio, such as the sample rate. If you are sending audio in the WebM format (or any format with a header), take care not to cut off the header. Avoid starting the audio stream when the WebSocket connection is not open. If you have implemented a mute button, test what happens when the chat starts while mute is enabled.
Linear PCM
PCM (pulse-code modulation) is a method of representing audio as a sequence of “samples” that capture the amplitude of the audio signal at regular intervals. PCM actually describes a family of different representations that vary along several dimensions: sample rate, number of channels, bit depth, and more. You must communicate these details to EVI in order for EVI to be able to interpret the audio correctly. PCM is a headerless format, so there is no way to communicate these details in the stream of audio data itself. Instead, you must send a session_settings message specifying the sample rate, the number of channels, and an encoding. Presently, the only supported encoding is linear16, which is the most common. It describes a linear quantized PCM encoding where each sample is a 16-bit signed, little-endian integer.
Ensure the details you specify in the session_settings message match the actual the audio you are sending. If the sample rate is incorrect, the audio may be distorted but still intelligible, which could interfere with EVI’s emotional analysis. It’s difficult to understand your user’s subtle emotional cues if they sound like Alvin and the Chipmunks.
Non-supported formats
Mulaw (or μ-law) is a non-linear 8-bit PCM encoding that is commonly used in telephony, for example, it is used by Twilio Media Stream API. This encoding is not presently supported by EVI. If you are receiving audio from a telephony service that uses mulaw encoding, you will need to convert.
Troubleshooting audio
Audio issues can surface in several different ways:
- Transcription errors - you may see an error message over the chat WebSocket like
followed by the chat ending. This results from an error that happened while attempting to transcribe speech from the audio you sent, and often indicates that the audimio is malformed.
- Unexpected silence - Another failure mode is when you send
audio_inputmessages, the user is speaking, but you do not receive any messages back, neitheruser_message, norassistant_message. This can happen when EVI believes it has successfully decoded the audio, but has assumed the wrong format, and while the bytes of your audio would contain speech if decoded in the correct format, they appear to be static or silence when decoded incorrectly.
Once you have observed a behavior that could indicate an audio issue, you can troubleshoot by directly inspecting the audio_input messages your application sends to EVI and attempt to decode it and play it back yourself.
You can find this by adding log statements to your application, or from the Network tab of your browser’s developer tools.
Observe outgoing Session Settings and Audio Input messages
If your application runs in a web browser, you can view all the transmitted WebSocket messages. Open the developer tools, navigate to the Network tab, filter for WS (WebSockets), select the request to /v0/evi/chat, select Messages (sometimes called Frames), and click on a message to see its value.
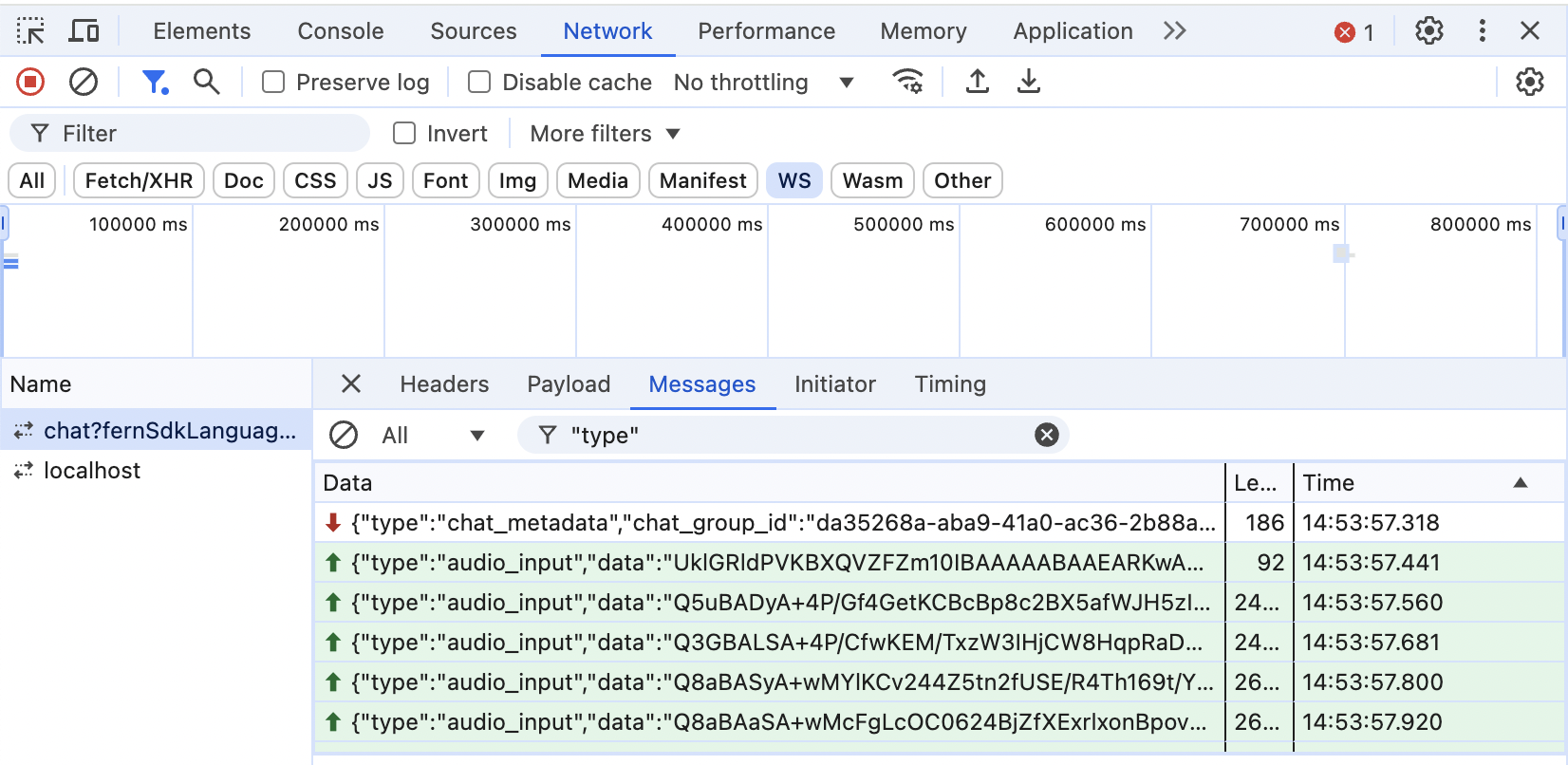
If your application is running on a server or a mobile device, you should add an appropriate log statement to your code so that you can observe the messages being sent to EVI.
Extract the audio data
Copy the value of the .data property in the first audio_input message your application sends. Paste it into your favorite text editor and save it into a temporary file /tmp/audio_base64. Then, use the base64 command to decode the base64 string into a binary file:
Analyze the audio
Download and install the FFmpeg command-line tool. (brew install ffmpeg, apt install ffmpeg, etc.) FFmpeg comes with a secondary command ffprobe for inspecting audio files. The ffprobe command is useful for audio formats that have headers, like WebM. Run ffprobe /tmp/audio to inspect the audio file, and if the audio is valid WebM, the output should include a line like
The ffprobe command is less useful for audio in raw formats like PCM, because technically any bytes can be validly interpreted as any raw audio format. You could even attempt to play a non-audio file like a .pdf as raw PCM: it will just sound like static. The only reliable way to analyze raw audio is to attempt to play them back. FFmpeg comes with a secondary command ffplay for playing audio.
To play linear16 PCM audio (the only raw format that EVI supports), run the command ffplay -f s16le -ar <sample rate> -ac <number of channels> /tmp/audio, replacing <sample rate> and <number of channels> with the values you specified in the session_settings message. If the audio is valid, you should hear the audio you recorded and attempt to send to EVI.
If you hear distorted audio, you may have specified the wrong sample rate or number of channels. If you hear static or silence, then the audio is likely not in the linear16 PCM format that EVI expects. In this case, you should add conversion step to your source code, where you explicitly convert the audio to the expected format. If you are unsure of the format that is being produced, you can experiment trying to play back with different PCM formats by changing the -f flag to s8, s16be, s24le, etc.